* nonsaturated neurons 이란? 어떤 입력 x가 양의 무한대로 증가할 때, 함수의 값이 무한대로 가는 것이며, non-saturating nonlinearity fuction의 대표적인 예가 ReLU이다. * softmax란? 활성화 함수(activation function) 중 하나인 소프트 맥스 함수는 다중 클래스 분류 모델을 만들 때 사용된다. 출력층에서 fc layer? 와 함께 사용되며, 결과를 확률 값으로서 해석할 수 있게 변환해준다. 높은 확률을 가지는 class로 분류하여 나타낸다. 즉 결과값을 정규화하는 것으로 생각할 수 있다. *활성 함수가 뭔데? 모델의 복잡도를 높히는 것 https://nittaku.tistory.com/267 본 논문에서 이루고자 했던 것 1. to make training faster 1) non saturated neurons 2) 2 GPU 2. to reduce overfitting in fc layers 1) dropout
1. Introduction
한계 제시
과거의 수만 장 정도로 적은 양의 dataset으로는 실제 사물 이미지를 인식하고 분류하기에는 한계가 있고, 더 큰 규모의 dataset을 가지고, 더 강력한 모델과 기술로 오버피팅을 예방해야 함.
ImageNet의 등장
22,000개의 카테고리에 1500만장이 넘는 고해상도 labeled image dataset의 등장 - 오버피팅을 줄이기 위한 / realistic 한 setting을 위한 대안으로 huge 데이터가 필요한데 imageNet 등장
커진 dataset을 감당하고 더 많은 데이터를 학습시키기 위해,
large learning capacity를 가지는 모델이 필요
CNN model을 사용한 이유
CNN은 depth나 breadth을 바꾸면서 조절이 가능하고, 이미지를 정확히 인식하는 데에 성능이 우수함. 또한, 일반적인 feedforward network와 다르게 더 적은 connection과 파라미터를 갖기 때문에 학습이 쉬움.
CNN은 큰 규모의 고해상도 이미지를 적용하기에는 굉장히 비싸지만, lucky하게 현 GPU는 큰 CNN을 학습시키기에 충분히 강력함. + recent datasets (ImageNet) contain enough labeled examples to train such models without 'overfitting'
본 논문에서 기여한 5가지 1. large CNN 중 하나를 학습하여 대회에서 뛰어난 성과를 낸 점 2. highly optimized GPU을 활용하여 2D convolution의 implementation과 CNN을 학습하는 방식을 공개한 점 3. training 시간을 단축할 새롭고 unusual한 구조를 사용한 점 4. 큰 크기로 인한 overfitting 문제를 다양한 방법으로 예방한 점 5. 5개의 convolution layer와 3개의 fully-connected layer 중 하나라도 없으면 성능이 확연히 떨어지는 점
즉, 모든 레이어가 중요한 역할을 수행하고 있음. depth is important
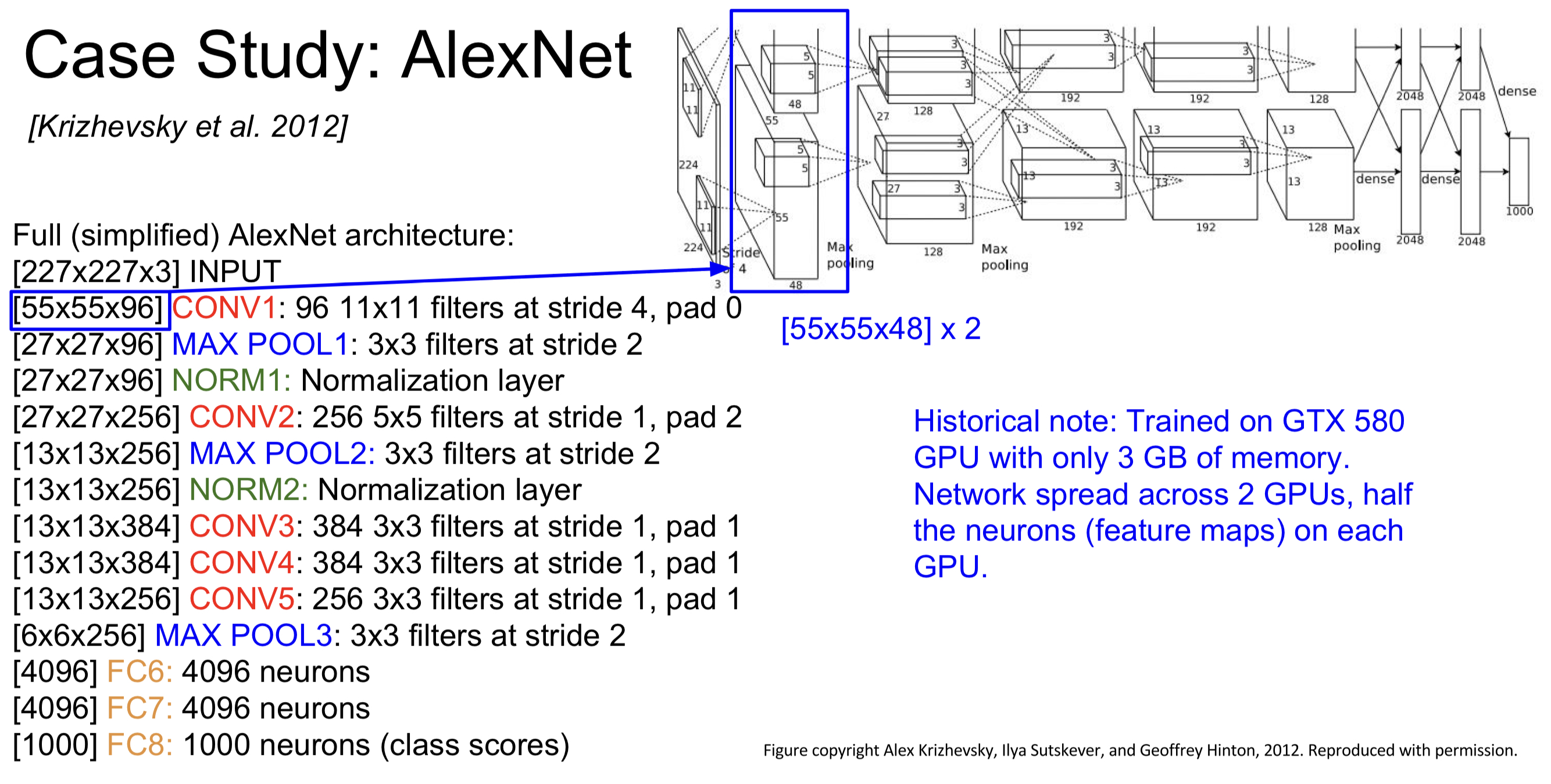
* 논문에 제시된 GPU를 사용하기 때문에, 8개의 layer로 구성되어 있으며, GPU 발전에 따라 성능이 향상될 여지가 충분함.
2. The Dataset
ImageNet 이란? 22,000가지의 카테고리로 나뉘며, 1500만장 이상의 고해상도 이미지 dataset
ILSVRC 대회에서는 ImageNet 카테고리 중 1000가지를 사용하였고,
120만장의 training 데이터, 5만 장의 validation 데이터, 15만장의 testing 데이터로 구성됨.
Error Rate
ImageNet에서는 일반적으로 두 가지 종류의 Error Rate를 사용
top-1 error:top-1 class가 실제 class와 같다면 top-1 error는 0%
top-5 error:top-5 class 중 실제 class와 같은 게 있다면, top-5 error는 0%
*ImageNet 대회에서는top-5 error5%이하가 되면 분류를 잘 했다고 볼 수 있음
Down-sampled Image
ImageNet은 여러 해상도의 이미지들로 구성되어 있지만, CNN model은 일정한 차원의 입력을 필요로 함.
어떻게 이미지를 자르는가?
1) 이미지의 가로, 세로 중 짧은 쪽을 256 pixel로 scaling 2) 나머지는 이미지의 중심 기준 256*256 으로 cut
*일반화 성능을 향상시키기 위해, 각 픽셀에서 mean activity를 빼서 각 픽셀을 centerize함.
Network architecture에 사용된 여러 방법들을 중요도 순으로 소개하고 있다.
3.1 ReLU Nonlinearity (Rectified Linear Unit)
ReLU를 사용한 4 conv neural network는 tanh 함수를 사용한 네트워크보다 6배 빠르게 0.25 training error rate에 도달
ReLU(Solid) - tanh(Dash)
Dash Line: f(x) = tanh or sigmoid = 일반적인 뉴런의 출력 함수
하지만 해당 activation function(활성 함수)는 gradient descent 방법으로 학습 시, saturated되어 학습 속도를 저하시킴.
Solid Line: f(x) = max(0,x)= 본 논문에서 제시한 대안
ReLU function : 어떤 x가 0보다 크면 x 출력, 0보다 작으면 0 출력
위 그래프를 보면, 같은 Training error rate에 대하여 ReLU(Solid) 를 사용했을 때, 더 적은 Epochs 값을 가진다는 것을 알 수 있으며,saturated 속도가 개선된다는 것을 확인할 수 있다.
타 논문에서 nonlinearity로 f(x) = |tanh(x)|를 채택
이는 overfitting을 방지하기 위함이며, 본 논문에서 ReLU를 사용하는 이유는 overfitting보다 performance, 즉 수렴 속도를 가속하여 학습 속도 저하를 방지하는 측면을 고려했기 때문임. ( Fasting learning -> high performance)
3.2 Training on Multiple GPUs
GPU 메모리 크기의 한계
GTX 580 GPU는 3GB 메모리를 가지기 때문에, 120만장의 training 이미지를 학습하기에 어려움.
+ 학습하는 네트워크의 최대 크기를 제한함.
-> 하나의 network를 두 개의 GPU에 나누어 할당하여 학습한다.
cross-GPU parallelization
커널을 반으로 나누어 각각의 GPU에 할당
두 개의 GPU 간의 communication은 특정 레이어들에서만 발생하도록 함.
layer 3 에서는 layer 2의 모든 커널 맵을 받아올 수 있지만, layer 4는 같은 GPU에 할당된 입력만을 받을 수 있게 함.
(부장님의 허락을 받지 않고 팀원끼리 커뮤니케이션 가능하다는 의미....)
어떤 레이어에서 어떤 패턴으로 입력을 주고 받고 연결되는지를 결정하는 것이 관건 - 어렵지만 하면 좋아진다
결과적으로 보면, columnar CNN 이랑 유사한데 열이 독립적이지 않다는게 AlexNet 시스템의 특징
Multiple GPUs 활용에 따른 성과
하나의 GPU를 활용하는 경우보다 top-1 & top-5 error rates 를 1.7%, 1.2% 줄였으며, 학습 시간 또한 조금 단축
3.3 Local Response Normalization
요즘은 Local Response Normalization보다 Batch normalization을 더 많이 쓴다고 함.
Input normalization이 필요하지 않은 ReLU ReLU는 saturating을 방지하기 위한 인풋 정규화가 필요하지 않다는 장점을 가짐
그래도 일반화에 도움이 되는 Local Normalization
ReLU 함수에 양수의 입력 값이 들어왔을 때, 그대로 출력하게 됨
상대적으로 큰 양수 값이 출력되면, 그로 인한 강한 자극이 주변의 작은 자극의 세기를 줄이기 된다.
implement the 'lateral inhibition' = 측면 억제
측면 억제란?
신경 생리학 용어로, 한 영역에 있는 신경 세포가 상호간 연결되어 있을 때, 중간 신경세포를 통해 이웃 신경 세포를 억제하려는 경향이다.
-> 헤르만 격자를 보자.
Lateral Inhibition : 헤르만 격자
상수 k,n,α,β은 hyper-parameter 값이며, 본 논문에서는 k=2, n=5, α=0.0001, β=0.75로 설정
검은 사각형 안에 흰 선이 지나가고 있음- 흰색 선에 집중하지 않을 때 회색 점이 보이는 것이 측면 억제에 의한 현상
즉 흰색으로 둘러싸인 측면에서 억제를 발생시키기 때문에 흰색이 반감되어 회색으로 보이는 것
Jarrett et al의 논문과 비교했을 때, local contrast normalization 측면에서 유사한 점이 있지만, 'brightness norm'에서mean activity를 substract하지 않기 때문에본 논문이 더욱 우수하다고 평가
왜 측면억제를 사용하나 ? ReLU 때문
a^i_(x,y): i번째 커널의 (x,y) 위치의 출력이 ReLU를 통과한 값
양수의 입력을 그대로 사용하는 ReLU의 경우 conv / pooling 을 했을 때, 상대적으로 매우 높은 픽셀 값이 주변에 영향을 미침. - 다른 활성 맵에 있는 같은 위치의 픽셀끼리 '정규화' 적용
만약 a^i_(x,y) 값이 상대적으로 큰 양수 값이라면, 같은 위치의 다른 커널 맵의 값을 가져와서, β 제곱을 한 뒤 나누어졌을 때, 비교적 영향을 많이 받아 작아질 것
큰 양수 값을 더 많이 줄여 큰 값으로 인한 자극이 주변에 주는 영향을 최소화
Local Response Normalization활용에 따른 성과
정규화를 수행하지 않는 것보다 top-1 & top-5 error rates 를 1.4%, 1.2% 줄임
CIFAR-10 dataset에 대해서도 정규화를 수행했을 때 error rate를 2% 줄임
3.4 Overlapping Pooling
CNN에서의 pooling layer는 같은 커널 맵에서의 이웃 뉴런들의 summary 제공
보통 pooling layer는 overlap하지 않음
pooling layer의 kernel 사이즈 = z
pooling layer의 stride 사이즈 = s
s=z 이면, 일반적인 overlap하지 않는 pooling layer
s<z 이면 overlapping pooling layer
본 논문에서는,z=3, s=2로 하여 overlapping pooling layer로 구성하여 overfitting을 방지함